
Everything a developer needs to know about Generative AI for SaaS
Few months ago, I knew almost nothing about AI. I used ChatGPT and Co-Pilot (I'm civilized, after all), but a lot of the content around AI was Greek to me. Terms like models, transformers, training, inference, RAG, attention, and agents were unfamiliar. Last week, I have completed my first end-to-end AI-based product: AI Code Assistant. It is a tool for exploring new code bases by chatting with a virtual “senior developer” who is deeply familiar with the code. In the journey to build a full-fledged AI product, I learned a lot about AI. At times I got a bit frusturated - each article and paper I've read had large amounts of jargon and assumed knowledge. I had to piece together the information from far too many sources. It was also a bit challenging to learn which topics were actually important, and which were just buzzwords.
So I decided to write a blog post that explains everything you need to know about generative AI for SaaS. It is going to be a two-part blog post. This blog will cover the main concepts of generative AI and retrieval-augmented generation (RAG). It has all the terminology you need to go out and learn more on your own. The next blog will cover the design and implementation of the AI code assistant.
Generative AI
Since everyone is familiar with ChatGPT, it is always a good place to start. ChatGPT is based on GPT, a “Generative pre-trained transformer.” Every word in this short description matters:
- Generative: It creates new content (as opposed to a search engine or a recommendation engine) based on its training.
- Pre-trained: The AI model is already trained on massive amounts of information (most of the internet). This makes ChatGPT (and other GPT models) useful out of the box. But not always the best fit when you want the answers to be based on a specific context, like a single GitHub repository.
- Transformer: This means the model is based on “transformer architecture,” as described in the groundbreaking paper “Attention is All You Need.” The architecture is a specialized neural network. I'm not going to even attempt to explain it - but the important idea is that transformers look at the input sentence as a whole and at the relations between the words in the sentence. And they do it for both the input and the output. This architecture allows ChatGPT to output grammatically correct sentences and to give the impression it “understands” your input. Unlike older generation models, which often took specific words out of context.
The use of models to answer questions or perform other tasks is called inference. The question is sometimes called a prompt and the response of the model is often called prediction. While a ChatGPT response doesn't really predict anything, the term is used because the model is trained to predict the next word in a sentence. The way the prompt is phrased can have a big impact on the response. The techniques of framing questions to models are called prompt engineering. And this is something that almost everyone that interacts with these models learns rather quickly. The same technique also applies when you develop applications.
For example, when developing the AI Code Assistant, one of the questions I asked was "How are tenants used in this project?" When prompted with "You are a helpful assistant, please answer the question based on the following documents", the model responded with:
Tenants are used in the project to associate todos with specific users or groups. Users can create a new tenant and add tasks specific to that tenant.
But when I prompted with: "you are a principal engineer answering questions from other engineers about code projects", the model responded with:
Tenants are used in the project to organize and isolate data for different users or groups. Each tenant has its own set of data stored in the database, such as todos. The relationship between tenants and todos can be seen in the SQL query:
select name, title, complete from tenants join todos on tenants.id=todos.tenant_idThis query retrieves the todos along with the associated tenant information, demonstrating how data is segmented based on tenants in the application."
Prompting the model with terms related to software engineering, like "principal engineer" and "code projects", led to a more detailed and accurate response.
The success of GPT gave rise to a large number of similar text-generation models, all based on the transformer architecture. Mistral7B, Llama, Claude, Gemini and many more. Since all these models are generative, pre-trained, and based on transformers, they share many of the same strengths and weaknesses, and can be easily interchanged in an AI application. They are often refered to as “GPT models”, "generative models" or "transformer models".
In addition to the text-generation models, that are based on transformers, there are other types of generative AI models. For example, image generation models like Dall-E, StableDiffusion and MidJourney are based on different combinations of GANs (Generative Adversarial Networks), diffusion models and transformers. This blog and the next in the series will focus on transformer-based generative models
The pre-training of GPT-type models is both their strength and their weakness: they know everything, but struggle when you need them to answer only based on specific things. Specific documentation, specific legal information, or a specific code base. Their tendency to hallucinate and generate incorrect information is a well-known problem. but it can be mitigated to a large extent.
The two main mechanisms to overcome this weakness are fine-tuning and retrieval-augmented generation (RAG):
-
Fine-tuning: Fine-tuning is a name for all the methods of training the pre-trained models. This training uses very large data sets of questions and answers (for example, fine-tuning a model to answer questions about coding by training it on StackOverflow and LeetCode data). HuggingFace maintains a large repository of data sets, many of which can be used for fine-tuning. When you hear about the race to acquire GPUs, it is typically for pre-training or for fine-tuning. Inference and prediction are much less computationally intensive than training. Fine-tuning is an active area of research and there are many techniques and algorithms for fine-tuning with different performance to resources tradeoffs. It is recommended to start fine-tuning with low-resources methods and only move to more resource-intensive methods if necessary. One thing to keep in mind if you fine-tune is that you need to track your experiments (iterations, versions, parameters, models) and evaluate the results. This is a non-trivial task, and there are many tools and services that can help you with it.
-
RAG: RAG is a much simpler approach since it can completely avoid additional training. The idea behind RAG is that you can present relevant information to the model when prompting it, and ask it to answer questions based on this information. It has been shown that the use of RAG leads to more accurate responses than the GPT models alone. Not surprisingly, the performance of the RAG technique depends on the quality of information you provide to the model. This means that getting highly relevant information to the model is the key problem for RAG.
To implement AI Code Assistant, I went with RAG approach. Getting specific responses based on the specific repository we are exploring is core to the project, and while we have all the necessary code, we don't have a large corpus of questions and answers for every codebase. Using RAG, the main technical challenge of the project will be to select a few highly-relevant snippets for each question and provide them to a text generation model.
RAG Concepts
How do we find relevant code snippets for each question? This is the main problem of RAG, and the solution has three parts: Preparing the data, storing the documents efficiently for retrieval and retrieving the documents. Storing and retrieving methods are highly intertwined since the storage has to be optimized for the retrieval method.
Putting together the data preparation, storage, and retrieval methods with the generative model in order to have an informed conversation with a generative model is retrieval-augmented generation (RAG). The general architecture of RAG-based application is illustrated in the figure below:
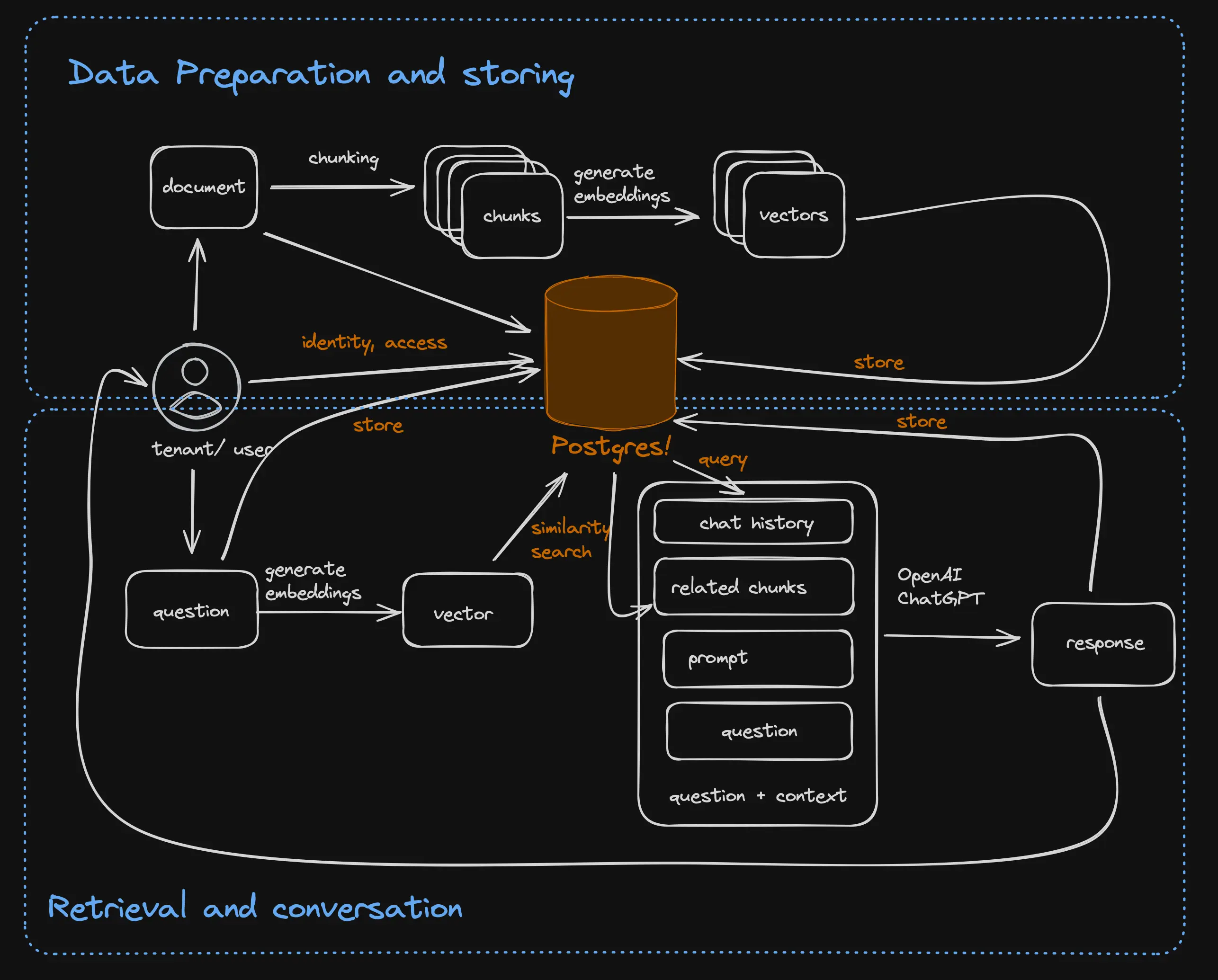
Data preparation
Before searching texts, we need to prepare the data. The quality of an RAG-based application heavily depends on the ability to retrieve relevant data, so proper preparation is a key part of any RAG application. These preparation steps depend on the data and use case. At a minimum, they involve splitting large documents into smaller ones in a process called chunking.
Chunking is important because you may encounter limits on the input text size and because providing the text generation model with smaller but more relevant chunks works better than providing the model with larger, somewhat relevant chunks. Imagine that I ask you about today's weather. If I handed you a large stack of newspapers, you'd probably have a harder time responding than if I handed you a single page with the weather forecast. This isn't just common sense; research shows that AI results degrade with large context windows.
In addition to chunking, some sources recommend removing common words from the input or normalizing, like adding spaces to achieve equal length of chunks. Whether or not this is necessary and which preparation steps are useful depends on the algorithm you use, and therefore it is best to rely on the algorithm documentation for suggestions rather than on random blogs. For example, I discovered that very little preparation is needed if you search using OpenAI's embedding algorithm - this is because the algorithm itself applies normalization and is not sensitive to whitespace, sentence length and other noise that otherwise you'll have to clean.
In cases where preparation is a complex multi-step process that involves handling different file formats, cleaning them up, validating, standardizing and chunking, the data preparation process can be quite complex. In such cases, it is recommended to use a data pipeline or workflow tool to abstract and manage the process.
Storing documents and retrieving
The choice of data store for search typically depends on the search algorithm, as different stores will be optimized for different algorithms. Text search algorithms are far from new. In fact, this may be the most popular type of algorithm on the internet. You use a text search engine to search for a movie on Netflix, a product on Amazon, or a document on Google Drive.
Today, there are two main types of text search, plus a hybrid approach:
Full-text search Full-text search is the more traditional approach. Text search algorithms rely on word frequency (how often the word appears in each text vs in general) and lexical similarity (The word “ice cream” is similar to “ice” and “cream” but not to “scoop” and “vanilla”). These algorithms can handle typos, synonyms, partial words, and fuzzy matching. These days, the state-of-the-art text search algorithm is BM25.
Vector search (also called semantic search) This method uses AI models, based on the transformer architecture, to find documents that are similar in meaning. These specially trained transformers (called embedding models or embedders) convert text to a vector (also called embedding). The vector doesn't represent exactly the words in the text but rather the semantic meaning of the text. The embedding model is trained on a giant corpus of texts (such as the entire internet), so it has “knowledge” of which terms are related. Once texts have been converted to vectors, you can check if any two texts are related by checking how close the two vectors are. When checking the similarity of texts using embeddings, it is expected that “ice cream” will be fairly close to “scoop” and “vanilla” since these words often show up next to each other.
The popular embedders are based on transformer models, fine tuned for the task of generating embeddings. And at this time we are starting to see specialized embedding models, pre-trained or fine-tuned for specific subsets of the language such as code, legalese or medical jargon. Words like "function", "class" and "variable" will be close to each other in the vector space of a code embedding model, but not in a general english-language model.
Hybrid In the hybrid approach, you use each method separately to find the closest matching text. Then, you combine the distance score from each method (the combination is typically weighted, and the scores have to be normalized first). Then, you re-rank the results based on the combined score and finally choose the highest-ranking documents based on the combined score. There are also a few embedding models (notably, BGE-M3) that combine the two methods in the same model, and use relevancy scores from each model to re-rank the results themselves.
Regardless of the method you choose, you will need a data store that can efficiently store and retrieve the vectors or the text based on these methods. Some data stores that specialize in one of the two algorithms, and a few offer both. Postgres happens to have extensions for both vector and text search.
Vector databases (and Postgres with pg_vector extension) have an efficient implementation of vector distance metrics, so you can order results by distance
(also called ranking) or efficiently find vectors within a certain distance of another vector. There are many distance metrics, and different databases support different
ones, the most common ones are: Cosine distance, the most popular distance metric for text search, and dot product which is more efficient but only works for normalized vectors.
In addition, vector databases have indexes that can make searching large collections of vectors even more efficient. These indexes are different from those you are familiar with because they are based on machine learning algorithms. These algorithms find close vectors very efficiently, even with millions of vectors. But they have accuracy and memory use tradeoffs. Because of the accuracy tradeoffs (also known as recall tradeoffs, since it looks like the database “forgot” some of the data), the algorithms used in the indexes are called ANN - approximate nearest neighbors (as opposed to KNN - the accurate results you get by fully scanning the vector collection). Because these indexes use machine learning techniques, creating them is often called training. Just don't get confused: this type of training fundamentally differs from the pre-training or fine-tuning of large language models.
Since every SaaS, including AI Code Assistant, needs much information besides embeddings, you also need a “normal database.” This makes pg_vector,
the vector embedding extension for Postgres, especially attractive. Pg_vector is trivial to use, but when performance, scalability, and tenant isolation matter,
there are some nuances that you should consider. We'll cover these in the next blog when we discuss implementation details of our Code Assistant example.
RAG in Action
In the next blog post, I'll show you how I put all these concepts together to build the AI Code Assistant, but meanwhile, lets peek now at a small example of how RAG works, so you are not left with just theory:
const { OpenAIEmbeddings } = await import("@langchain/openai");
const { Nile } = await import("@niledatabase/server");
const EMBEDDING_MODEL = "text-embedding-3-large";
const OPEN_API_KEY = "bring your own key";
const NILEDB_USER = "we use nile as the vector store, so we need a user";
const NILEDB_PASSWORD = "and their password";
let model = new OpenAIEmbeddings({
apiKey: OPEN_API_KEY,
model: EMBEDDING_MODEL,
dimensions: 1024, // we'll explain why in the next blog
});
let nile = await Nile({
user: NILEDB_USER,
password: NILEDB_PASSWORD,
});
// some documents:
const documents = [
"JavaScript is a programming language commonly used in web development.",
"Node.js is a runtime environment that allows you to run JavaScript on the server side.",
"React is a JavaScript library for building user interfaces.",
];
// embed docs
let vectors = await model.embedDocuments(documents);
// store embeddings
await nile.db.query(
"CREATE TABLE IF NOT EXISTS embeddings (id integer, embedding vector(1024));"
);
for (const [i, vec] of vectors.entries()) {
await nile.db.query(
"INSERT INTO embeddings (id, embedding) values ($1, $2)",
[i, JSON.stringify(vec.map((v) => Number(v)))]
);
}
// now lets ask a question
let question_vec = await model.embedDocuments(["Tell me about React"]);
// search for the nearest document by cosine distance of embedding
let answer_vec = (answer_vec = await nile.db.query(
"select id from embeddings order by embedding<=>$1 limit 1",
[JSON.stringify(question_vec[0])]
));
// return the answer:
console.log(
"based on your question, this document is relevant: " +
documents[answer_vec.rows[0].id]
);
As you can see, in the example, we use OpenAI to embed the documents, store the embeddings in a database, and then search for the nearest document based on the cosine distance of the embeddings. Each one of these actions is one line of code and a step in the RAG process.
AI in SaaS
The concepts above will come up again and again as you build AI applications and they are important no matter what application you are building. But if you are building AI SaaS - where AI is part of a service that you are offering other companies, you have more problems to worry about. Since Code Assistant was designed as SaaS - we'll discuss our approach to these problems in the implementation blog.
- Scale and elasticity: SaaS companies can have anything from 3 customers to 500,000, and there is significant variance between the amounts of storage and compute used by any customer. This makes it quite difficult to scale out the database, and even more so when combining traditional OLTP storage with vector store - each with its own memory and compute demands. Embeddings can grow large really fast, since each customer brings their own data set - of unknown side and quality. We have to figure out how to scale the database as the number of customers and the dataset of individual customers grow.
- Latency: In many SaaS applications, latency is critical. Good examples of this are Github Co-Pilot and Grammarly. These apps need to keep up with human typing speed, otherwise their suggestions are useless. There are many places to reduce latency - efficient indexing, smart provisioning of memory and compute, and the most underrated of all - placing the data close to the customer, to minimize network latency.
- Fine-tuning: Not every SaaS requires fine-tuning of models, but those who do must be very careful around use of their customer's data for such this. The risk of a single model accidentally revealing data of one customer to another because data from both customers was used in training is high - and SaaS customers are quite savvy about these risks. Fine tuning is already one of the most challenging aspects of AI applications, adding the challenges of protecting customer's data - and you have potential for either great trouble or great competitive advantage - depending on how you approach this.
Now that you are familiar with all the useful AI and RAG concepts, you are ready for the next blog, where we'll discuss the design and implementation of the AI code assistant. Of course, if you are impatient, you can always sign up to Nile and start building your own AI SaaS application.